[NODE 강의] 크롤링 (Crawling) - 배송위치 추적
[클립명]
1. 크롤링개요
2. 배송위치 추적
3. puppeteer 1 ~ 2

Crawling
웹 크롤러(web crawler)는 조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램이다.
웹 크롤러가 하는 작업을 '웹 크롤링'(web crawling) 혹은 '스파이더링'(spidering)이라 부른다. 검색 엔진과 같은 여러 사이트에서는 데이터의 최신 상태 유지를 위해 웹 크롤링한다. 웹 크롤러는 대체로 방문한 사이트의 모든 페이지의 복사본을 생성하는 데 사용되며, 검색 엔진은 이렇게 생성된 페이지를 보다 빠른 검색을 위해 인덱싱한다. 또한 크롤러는 링크 체크나 HTML 코드 검증과 같은 웹 사이트의 자동 유지 관리 작업을 위해 사용되기도 하며, 자동 이메일 수집과 같은 웹 페이지의 특정 형태의 정보를 수집하는 데도 사용된다.
웹 크롤러는 봇이나 소프트웨어 에이전트의 한 형태이다. 웹 크롤러는 대개 시드(seeds)라고 불리는 URL 리스트에서부터 시작하는데, 페이지의 모든 하이퍼링크를 인식하여 URL 리스트를 갱신한다. 갱신된 URL 리스트는 재귀적으로 다시 방문한다. (위키백과 발췌)
--------
즉, 내가 데이터를 얻고 싶은 Seed Url을 주면, 해당 페이지의 콘텐츠를 가져와서 분석하고 원하는 데이터를 추출하고, 분석한 데이터들을 색인화하여 보다 빠른 검색이 가능하도록 해주며, 하이퍼링크가 걸린 사이트가 있다면 해당 사이트까지 방문하여 이 작업을 계속 반복하는 것이다. 구글, 네이버, 다음 등의 검색엔진 계속하여 수행하고 있는 작업이기도 하다. 웹크롤링은 웹사이트가 많아짐에 따라 어떻게 하면 좀 더 효율적으로 크롤링을 수행할 수 있을지에 대한 연구가 계속되고 있다고 한다.
웹크롤링에 대해 관심이 있다면 아래 글을 꼭 한 번 읽어보자.
배송 추적하기
이번에는 대한통운 택배조회 사이트에서 배송위치를 추적하는 강의를 보면서 같이 연습해보려고 한다.
우선 필요한 패키지를 설치한다. (2021년 3월 기준 : 아래 패키지들은 모두 deprecated 상태)
$ npm install request
$ npm install request-promise
// 크롤링한 데이터의 특정 부분을 parse할 때 사용
$ npm install cheerio👁🗨 request 패키지는 2020년 2월부로 deprecated 상태(request-promise 도 마찬가지)이며, 현재는 유지보수 모드로 들어가 있는 상태이다. 아직까지는 사용하는 데는 문제는 없지만, 이제 막 nodejs로 프로젝트를 시작하는 분들이 있다면 deprecated 상태의 라이브러리를 쓰기 보다는 대체 라이브러리를 고민해봐야 한다. (대체 라이브러리 목록)
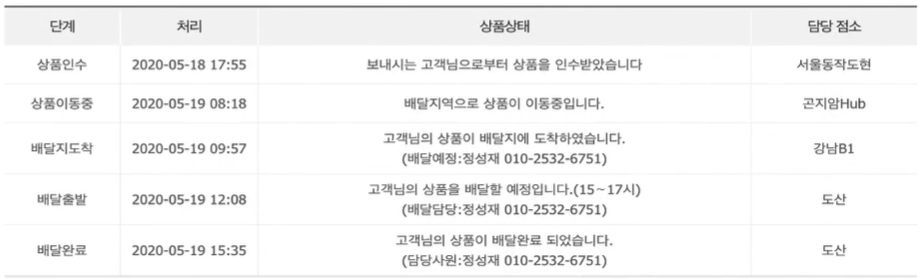
코딩 흐름은 크게 3단계이다.
① request 모듈을 이용하여 원하는 페이지에서 html 콘텐츠를 모두 가져온다.
② 가져온 데이터에서 원하는 영역을 감싸고 있는 부분을 제이쿼리+CSS선택자를 이용하여 지정한다.
③ 지정한 영역의 html 구조를 실제로 원하는 데이터만 추출해낸다.
아래 코드를 살펴보자.
const express = require('express');
// 모듈선언
const request = require('request-promise');
const cheerio = require('cheerio');
const app = express();
const port = 3000;
//json 데이터를 좀 더 보기 좋게 설정
app.set('json spaces', 2)
app.get('/shipping/:invc_no', async (req,res) => {
try{
//대한통운의 현재 배송위치 크롤링 주소
const url = "https://www.doortodoor.co.kr/parcel/ \
doortodoor.do?fsp_action=PARC_ACT_002&fsp_cmd=retrieveInvNoACT&invc_no=" + req.params.invc_no ;
let result = []; //최종 보내는 데이터
//① request 모듈을 이용하여 원하는 페이지에서 html 콘텐츠를 모두 가져온다.
const html = await request(url);
const $ = cheerio.load( html ,
{ decodeEntities: false } //한글 변환
);
//② 가져온 데이터에서 원하는 영역의 유니크한 html 태그를 제이쿼리+CSS선택자를 이용하여 지정한다.
const tdElements = $(".board_area").find("table.mb15 tbody tr td"); //td의 데이터를 전부 긁어온다
//한 row가 4개의 칼럼으로 이루어져 있으므로, 4로 나눠서 각각의 줄을 저장한 한줄을 만든다
var temp = {}; //임시로 한줄을 담을 변수
for( let i=0 ; i<tdElements.length ; i++ ){
//③ 각 영역의 특성을 파악하여 실제로 원하는 데이터만 추출해낸다.
if(i%4===0){
temp = {}; //시작 지점이니 초기화
temp["step"] = tdElements[i].children[0].data.trim(); //공백제거
//removeEmpty의 경우 step의 경우 공백이 많이 포함됨
}else if(i%4===1){
temp["date"] = tdElements[i].children[0].data;
}else if(i%4===2){
//여기는 children을 1,2한게 배송상태와 두번째줄의 경우 담당자의 이름 br로 나뉘어져있다.
// 0번째는 배송상태, 1은 br, 2는 담당자 이름
temp["status"] = tdElements[i].children[0].data;
if(tdElements[i].children.length>1){
temp["status"] += tdElements[i].children[2].data;
}
}else if(i%4===3){
temp["location"] = tdElements[i].children[1].children[0].data;
result.push(temp); //한줄을 다 넣으면 result의 한줄을 푸시한다
}
}
res.json(result);
}catch(e){
console.log(e)
}
});
app.listen( port, function(){
console.log('Express listening on port', port);
});npm start로 서버를 구동하고, 웹브라우저에서 'http://localhost:3000/shipping/실제송장번호' 를 입력하면 배송추적에 관련된 데이터들이 json 형태로 화면에 출력되는 것을 확인할 수 있다.
[핵심]
타겟 웹페이지에서 내가 필요한 데이터를 감싸는 태그들의 규칙을 찾아서 원하는 데이터만 추출해내는 것이다.
크롬 개발자 도구를 이용하여 태그들의 규칙을 찾을 수 있다. (크롬 브라우저에서 우클릭 - 검사 선택)
[주의사항]
타겟 웹페이지에서 특정 부분의 HMTL 태그를 CSS선택자로 추출하기 때문에, 타겟 웹페이지의 HTML 태그 구조가 변경되면 제대로 작동되지 않을 수 있다는 단점이 있다.